In this tutorial, you will receive a gentle introduction to training your first Emotion Detection System using the PyTorch Deep Learning library. And then, in the next tutorial, this network will be coupled with the Face Recognition network OpenCV provides for us to successfully execute our Emotion Detector in real-time. Let’s get started.
Today’s tutorial is part one in our two-part series of building our emotion detection system using PyTorch:
- Training an Emotion Detection System from Scratch using PyTorch (this tutorial)
- Real-time Emotion Detection using PyTorch and OpenCV (next tutorial)
Can Computers Do a Better Job than Us in Accessing Emotional States?
Humans are well-trained in reading the emotions of others. In fact, at just 3 months old, babies can already sense the mood of adults, whether they are happy or sad. Even Jennifer E. Lansford, PhD said:
From birth, infants pick up on emotional cues from others. Even very young infants look to caregivers to determine how to react to a given situation
Jennifer E. Lansford, PhD, a professor with the Social Science Research Institute and the Center for Child and Family Policy at Duke University
Now to provide a responsive answer to this question if “Computer’s can do a better job than us in accessing emotional states”, I designed a deep learning neural network that gives my computer the ability to make inferences about the emotional states of different people commenting on Novak’s situation—in simple words, giving them the eyes to see and understand how we as humans interpret different individuals reactions to certain situations.
Before starting with these tutorials, it’s important to be aware that our human emotions constantly change at every given second, as we can never be truly 100% happy or 100% sad. Rather, we show signs of mixed emotions together.
For example, when experiencing this situation based on different responses to the situation concerning his ban, people showed signs on been Surprised or in Fear; Happy or Sad; Angry or Neutral.
So rather than simply assigning a single label to each video frame we are analyzing, it will be more reasonable to represent our results in the form of probabilities that can then be further studied and analyzed in much depth.
Dataset

Source: https://bit.ly/3sf1R7e
For this tutorial, we will be utilizing the Facial Expression Recognition 2013 Dataset (FER2013) for the project. According to sources, this dataset was curated by Goodfellow et al. in their 2013 paper, Challenges in Representation Learning: A report on three machine learning contests.
It’s also great to know the facial expression datasets, also called FER2013, can be found on this Kaggle page, where you can download the dataset and start using it.
Additionally, you should be aware the data consists of 48 x 48 pixel grayscale images of faces with different expressions hidden behind each of them. And it’s also crucial to be aware the faces are more or less centered and are all resized to the specified pixel size.
The major goal was to categorize each face based on the emotion shown among one of the seven categories. Which is now six, as we’ve combined Anger with Disgust since they were only a few samples within the disgust folder. So the existing labels are:
- 0 = Angry
- 1 = Fear
- 2 = Happy
- 3 = Sad
- 4 = Surprise
- 5 = Neutral
Overall, we have to total training set which consists of 28,709 examples.
Note: this was inspired by Jostine Ho on his github repo, Facial Emotion Recognition.
Configuring your Development Environment
To successfully follow this tutorial, you’ll need to have the necessary libraries: PyTorch, OpenCV, scikit-learn and other libraries installed on your system or virtual environment.
Good thing you don’t have to worry too much about OpenCV and scikit-learn installation techniques, as I’ve covered them in this tutorial here. Mostly for Linux users. As you can easily pip install them, and you’re ready to go.
However, if you are configuring your development environment for PyTorch specifically, I recommend you follow their Installation guild on their website. Trust me when I say it’s easy to use, and you’re ready to go asap.

All that’s required of you is to select your preferences and run the install command inside of your virtual environment, via the terminal.
Project Structure
Before we get started implementing our Python script for this tutorial, let’s first review our project directory structure:
 →
→ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | $ tree . --dirsfirst . ├── dataset │ ├── test [6 categories] │ └── train [6 categories] ├── model │ ├── deploy.prototxt.txt │ └── res10_300x300_ssd_iter_140000_fp16.caffemodel ├── neuraspike │ ├── __init__.py │ ├── config.py │ ├── emotionNet.py │ └── utils.py ├── output │ ├── model.pth │ └── plot.png ├── emotion_detection.py ├── requirements.txt └── train.py 4 directories, 11 files |
We have five Python scripts to review today:
emotionNet.py:Our PyTorch implementation of the Custom EmotionNet architectureconfig.py:Stores the Networks Hyper-parameters and file paths.utils.py:This contains additional methods to help prevent our network from over-fitting while training.__init__.py: Let the Python interpreter know the directory contains code for a Python module and acts as a constructor for theneuraspikepackage.train.py:Trains the model on the FER2013 dataset using PyTorch, then serializes the trained model to disk (i.e., model.pth)
The model directory is where the deep learning-based face detector architecture (deploy.protxt.txt) and the Caffe model weights (res10_300x300_ssd_iter_140000_fp16.caffemodel) are been stored.
And finally, within the output directory is where the plot.png (a training/validation loss and accuracy) and model.pth (our trained emotion detection model file) will reside once the train.py file is executed.
With our project directory structure reviewed, let’s move on to training our custom EmotionNet Detector using PyTorch.
Implementing the Training Script for Emotion Detection
First, make a new script, naming it config.py, and insert the following code:
1 2 3 4 5 6 7 8 | # import the necessary packages import os # initialize the path to the root folder where the dataset resides and the # path to the train and test directory DATASET_FOLDER = f'dataset' TRAIN_DIRECTORY = os.path.join(DATASET_FOLDER, "train") TEST_DIRECTORY = os.path.join(DATASET_FOLDER, "test") |
The os module allows us to build a portable way of accessing folder paths directly in our config file, making it easy to use.
From Lines 6 – 8, we defined the path to where our input dataset is kept and also the path to our training and testing split.
15 16 17 18 19 20 21 22 | # initialize the amount of samples to use for training and validation TRAIN_SIZE = 0.90 VAL_SIZE = 0.10 # specify the batch size, total number of epochs and the learning rate BATCH_SIZE = 16 NUM_OF_EPOCHS = 50 LR = 1e-1 |
Since we don’t have any validation samples available, we’ll define our split percentage to use relatively 90% of the available data for training, while the remaining 10% will be used for validation (Lines 16 – 17).
Finally, the initialize batch size, number of epochs, and learning rate are defined from Lines 20 – 22.
Creating our EmotionNet Architecture Script
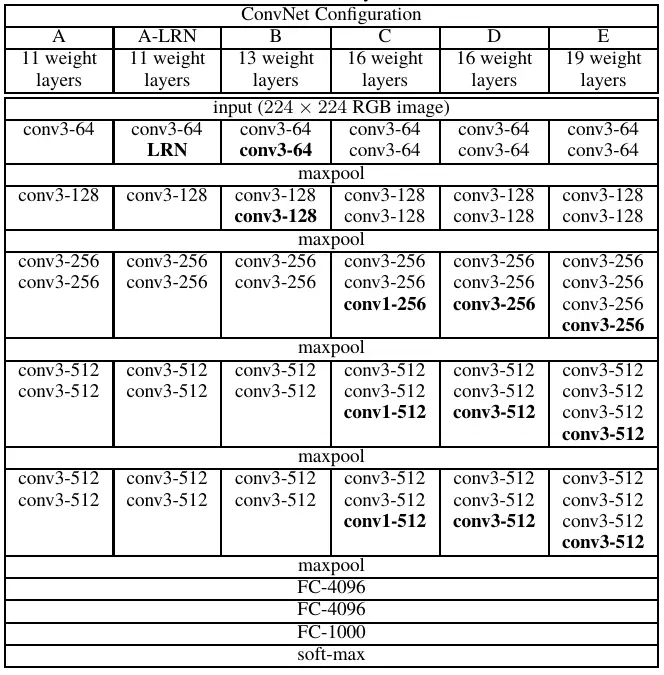
The network we will implement today was inspired by the VGG13 architecture. However, due to the lower performance we got after multiple experimentation, It’s more of a VGG13 network with a little tweak to fully connected layer and the activation functions used throughout the network.
So open a new script, naming it emotionNet.py, and let’s roll:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # import the necessary packages import torch.nn as nn import torch.nn.functional as F class EmotionNet(nn.Module): network_config = [32, 32, 'M', 64, 64, 'M', 128, 128, 'M'] def __init__(self, num_of_channels, num_of_classes): super(EmotionNet, self).__init__() self.features = self._make_layers(num_of_channels, self.network_config) self.classifier = nn.Sequential(nn.Linear(6 * 6 * 128, 64), nn.ELU(True), nn.Dropout(p=0.5), nn.Linear(64, num_of_classes)) |
We’ll start by importing the Python package we’ll need for designing our custom EmotionNet architecture (Lines 2 – 3).
We then defined our EmotionNet class on Line 6, which inherits the properties from PyTorch’s neural network module.
Within the __init__ method of the EmotionNet class it takes only 2 arguments when instanciated, which are:
num_of_channels: The type of image we want to pass as an input, either RGB (3) or GrayScale (1) in our case.num_of_classes: The total categories available within our dataset.
On line 11 the features attribute is initialize by making a call to the _make_layer function which will go through soon, however what it does is it builds the convolution layer of the VGG13 network based on the config parameters (network_config) defined on line 7.
Next the classifier attribute is the fully connected layer which is followed after the convolution layers. Here we only have 2 linear layers in total. The first layer includes the ELU activation function and a Dropout layer, with a probability of 0.5 (Lines 12 – 15).
17 18 19 20 21 22 23 | # instructs pytorch how to execute the defined layers in the network def forward(self, x): out = self.features(x) out = out.view(out.size(0), -1) out = F.dropout(out, p=0.5, training=True) out = self.classifier(out) return out |
After the initialization, our network wouldn’t know how each layer is been ordered. In order for PyTorch to know what layer follow after another:
self.features: Receive the input image and pass it through the convolutional layer (Line 19).self.view(out.size(0), -1): Flatten the output of the convolutional layer for it outputs to be served as an input into the fully connected layer –self.classifier(Line 20 – 23).
25 26 27 28 29 30 31 32 33 34 35 36 | # generate the convolutional layers within the network def _make_layers(self, in_channels, cfg): layers = [] for x in cfg: if x == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), nn.BatchNorm2d(x), nn.ELU(inplace=True)] in_channels = x return nn.Sequential(*layers) |
Finally, the _make_layer function, which receives the in_channel and cfg ( the network configuration).
Within the function, we initialize an empty list can layer which will hold the following layers:
- Convolutional 2D block
- BatchNormalization
- Elu (activation function)
- Max pooling layer
Inside the for loop Lines 28 – 35, we iterate through each output channels the network should produce. On Line 29, we check if the current value inside of the network configuration is M — that translates to max-pooling. If that’s the case, the max-pooling operation is then appended into the layers list (Lines 29 – 30).
If that’s not the case, the nn.Conv2D using a kernel_size of 3 and a padding of 1, nn.BatchNorm2d and ELU activation function are appended into the list (Lines 31 – 34). Then we’ll update the in_channels after the following operations (Line 35).
Finally, we return all the layers in a Sequential manner (Line 37).
Implementing our PyTorch Utilis Script
We’ll implement two callback functions to achieve better results and avoid our network from over-fitting while training.
First, we have the following:
- Learning Rate Scheduler, and
- Early Stopping.
Let’s have a look at the Learning rate scheduler.
If you’ve ever had some experience training deep neural networks, you’ll know some of the major issues when working with these networks are:
- They tend to over-fit very easily or might become difficult to train when you have an insufficient amount of datasets.
- Secondly, using a fixed learning rate is quite tricky to deal with.
Another way to handle the issue of using a fixed learning rate is to implement a learning rate scheduler that will dynamically decrease the learning rate while training. From what I know, there are a few hacks to doing this; however, the most commonly used method is to check if the validation loss doesn’t improve after a certain number of epochs.
So, open a new script, naming it utils.py, and insert the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | # import the necessary libraries from torch.optim import lr_scheduler import cv2 class LRScheduler: """ Check if the validation loss does not decrease for a given number of epochs (patience), then decrease the learning rate by a given 'factor' """ def __init__(self, optimizer, patience=5, min_lr=1e-6, factor=0.5): """ :param optimizer: the optimizer we are using :param patience: how many epochs to wait before updating the lr :param min_lr: least lr value to reduce to while updating :param factor: factor by which the lr should be updated :returns: new_lr = old_lr * factor """ self.optimizer = optimizer self.patience = patience self.min_lr = min_lr self.factor = factor self.lr_scheduler = lr_scheduler.ReduceLROnPlateau(self.optimizer, mode="min", patience=self.patience, factor=self.factor, min_lr=self.min_lr, verbose=True) def __call__(self, validation_loss): self.lr_scheduler.step(validation_loss) |
We’ll start by importing the Python package we’ll need. We’ll use lr_scheduler from the torch.optim package to help decrease the learning rate while training.
We then define our LRScheduler class on Line 5. This call will embody all the necessary logic to help control the learning rate while training the network.
The __init__ method of the LRScheduler takes only five arguments, which are:
optimizer:the optimizer we are using, for example, SGD, ADAM, etc.patience:how many epochs to wait before updating the learning ratemin_lr:least learning rate value to reduce to while updatingfactor:the factor by which the learning rate should be updatedlr_scheduler:the learning rate scheduler we will be using. You can learn more about theReduceLROnPlateauscheduler here.
And Secondly, on Lines 30 – 31, we then define our __call__ method, which executes the LRScheduler class whenever the validation loss as an argument is supplied to the object of the LRScheduler class.
Moving on, let’s implement the code to enable early stopping. Still, within the same utils.py script, add the following lines below:
34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | class EarlyStopping: """ Early stopping breaks the training procedure when the loss does not improve over a certain number of iterations """ def __init__(self, patience=10, min_delta=0): """ :param patience: number of epochs to wait stopping the training procedure :param min_delta: the minimum difference between (previous and the new loss) to consider the network is improving. """ self.early_stop_enabled = False self.min_delta = min_delta self.patience = patience self.best_loss = None self.counter = 0 |
Apart from the Learning rate scheduler, which we’ve implemented, the Early stopping mechanism is another technique to prevent our neural network from over-fitting on the training data.
While training your network, you might have experienced a situation where your training/validation loss is starting to diverge. And some possible cases this happens is when:
- Your network is beginning to over-fit, or
- the learning rate scheduler you’ve implemented isn’t helping the model learn anymore.
Moving on towards the implementation, we defined our EarlyStopping class on Line 35. This call will encapsulate all the necessary logic to help control the learning rate while training the network.
The __init__ method of the EarlyStopping accepts only two variables, which are:
patience:total number of epochs to wait to stop the training procedure.min_lr:the minimum difference between (previous and the new loss) to consider the network is improving.
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | def __call__(self, validation_loss): # update the validation loss if the condition doesn't hold if self.best_loss is None: self.best_loss = validation_loss # check if the training procedure should be stopped elif (self.best_loss - validation_loss) < self.min_delta: self.counter += 1 print(f"[INFO] Early stopping: {self.counter}/{self.patience}... \n\n") if self.counter >= self.patience: self.early_stop_enabled = True print(f"[INFO] Early stopping enabled") # reset the early stopping counter elif (self.best_loss - validation_loss) > self.min_delta: self.best_loss = validation_loss self.counter = 0 |
Next, the __call__ method defined enables us to execute the EarlyStopping class whenever the validation loss as an argument is supplied to the object of the EarlyStopping class.
The logic within this function is quite straightforward. We check the condition statements (Lines 60 – 66) if the difference between the previous and current loss is smaller than min_delta (meaning our model is starting to memorize instead of generalizing) initiate the counter. And once the counter variable is either equal to or surpasses the patience value, the network will automatically stop training.
Otherwise, if our network starts learning, the counter will be reset (Lines 69 – 71).
__init__.py
Within the __init__.py file, copy and paste the following code into your script to enable you to utilize the functions built within this package while training our model.
1 2 3 4 5 | # import necessary modules from .emotionNet import EmotionNet from .utils import EarlyStopping from .utils import LRScheduler from .config import * |
Creating our PyTorch training script
With our configuration file implemented, let’s create our training script with PyTorch.
Now go head, and open the train.py script within your project directory structure, and let’s get started:
A general overview of what will be doing, includes the following:
- Preparing our data loading pipeline
- Initializing the
EmotionNetnetwork and training parameters - Structuring the training and validation loop
- Visualizing the training/validation loss and accuracy
- Then, analysis the test samples with the trained model.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # import the necessary libraries from torchvision.transforms import RandomHorizontalFlip from torch.utils.data import WeightedRandomSampler from sklearn.metrics import classification_report from torchvision.transforms import RandomCrop from torchvision.transforms import Grayscale from torchvision.transforms import ToTensor from torch.utils.data import random_split from torch.utils.data import DataLoader from neuraspike import config as cfg from neuraspike import EarlyStopping from neuraspike import LRScheduler from torchvision import transforms from neuraspike import EmotionNet from torchvision import datasets import matplotlib.pyplot as plt from collections import Counter from datetime import datetime from torch.optim import SGD import torch.nn as nn import pandas as pd import argparse import torch import math |
On Lines 2-24, we import the necessary Python modules, layers, and activation functions from PyTorch, which we will use while training our model. These imports includes a number of well-known packages such as:
RandomHorizontalFlip: Horizontally flip our image randomly with a given probability.WeightedRandomSampler: It helps samples the elements based on the passed weights used for handling the imbalanced dataset.classification_report: To display the summary of the precision, recall, F1 score for each class on our testing set.Grayscale: A function that Converts an image from RGB into grayscale.ToTensor: A processing function that conversion data types into Tensors.random_split: Randomly splits our training dataset into a training/validation set of given lengths.DataLoader: An efficient data generation pipeline allows us to quickly build and train our EmotionNet.EarlyStopping: Our PyTorch implementation of the early stopping mechanism stops the training process if there’s no improvement after a given number of epochs.LearningRateScheduler: Our PyTorch implementation of the learning rate scheduler to adjust the learning rate.transforms: Compose several image transformations techniques to apply to our input images.datasets: Provides the ImageFolder function that helps read images from folders using PyTorch.EmotionNet: Our Custom PyTorch implementation of the neural network architecture for training our dataset.SGD: PyTorch’s wrapper for the stochastic gradient descent algorithm with momentum.nn: PyTorch’s neural network package.
Let’s now parse our command-line arguments and then determine whether we’ll be using our CPU or GPU:
26 27 28 29 30 31 32 33 34 | # initialize the argument parser and establish the arguments required parser = argparse.ArgumentParser() parser.add_argument('-m', '--model', type=str, help='Path to save the trained model') parser.add_argument('-p', '--plot', type=str, help='Path to save the loss/accuracy plot') args = vars(parser.parse_args()) # configure the device to use for training the model, either gpu or cpu device = "cuda" if torch.cuda.is_available() else "cpu" print(f"[INFO] Current training device: {device}") |
We have to parse two command-line arguments:
--model: The path to where the trained model will be saved (to then use it to run our real-time emotion detection system).--plot: The path to output our training history plot.
On lines 33 – 34, we’ll check which device is available to utilize when training our model—either CPU or GPU.
36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | # initialize a list of preprocessing steps to apply on each image during # training/validation and testing train_transform = transforms.Compose([ Grayscale(num_output_channels=1), RandomHorizontalFlip(), RandomCrop((48, 48)), ToTensor() ]) test_transform = transforms.Compose([ Grayscale(num_output_channels=1), ToTensor() ]) # load all the images within the specified folder and apply different augmentation train_data = datasets.ImageFolder(cfg.TRAIN_DIRECTORY, transform=train_transform) test_data = datasets.ImageFolder(cfg.TEST_DIRECTORY, transform=test_transform) # extract the class labels and the total number of classes classes = train_data.classes num_of_classes = len(classes) print(f"[INFO] Class labels: {classes}") |
Lines 38 – 43 calls the Compose instance from the torchvision.transforms module to transform each image in the dataset into grayscale, performs a RandomHorizontalFlip and RandomCrop (to augment the dataset during training), then convert the data-type into tensors.
The same techniques are applied for the testing/validation set (Lines 45– 48), except the RandomHorizontalFlip and RandomCroptechniques.
On Lines 51– 52, we are using the ImageFolder method from the torchvision.dataset package which is responsible for loading images from our train and test folders into a PyTorch dataset.
Then lines 55– 57, we extract the class labels and the total number of classes available.
57 58 59 60 61 62 63 64 65 66 67 | # use train samples to generate train/validation set num_train_samples = len(train_data) train_size = math.floor(num_train_samples * cfg.TRAIN_SIZE) val_size = math.ceil(num_train_samples * cfg.VAL_SIZE) print(f"[INFO] Train samples: {train_size} ...\t Validation samples: {val_size}...") # randomly split the training dataset into train and validation set train_data, val_data = random_split(train_data, [train_size, val_size]) # modify the data transform applied towards the validation set val_data.dataset.transforms = test_transform |
From there, we are creating validation samples from the training set available by computing the number of training/validation splits (currently set to 90% for training in our config.py script and the remaining 10% for validation).
Next, the validation split is based on the training set — 10% of the training set will be labeled as validation samples, then we will modify the data transform applied to the validation images.
71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 | # get the labels within the training set train_classes = [label for _, label in train_data] # count each labels within each classes class_count = Counter(train_classes) print(f"[INFO] Total sample: {class_count}") # compute and determine the weights to be applied on each category # depending on the number of samples available class_weight = torch.Tensor([len(train_classes) / c for c in pd.Series(class_count).sort_index().values]) # initialize a placeholder for each target image, and iterate via the train dataset, # get the weights for each class and modify the default sample weight to its # corresponding class weight already computed sample_weight = [0] * len(train_data) for idx, (image, label) in enumerate(train_data): weight = class_weight[label] sample_weight[idx] = weight # define a sampler which randomly sample labels from the train dataset sampler = WeightedRandomSampler(weights=sample_weight, num_samples=len(train_data), replacement=True) # load our own dataset and store each sample with their corresponding labels train_dataloader = DataLoader(train_data, batch_size=cfg.BATCH_SIZE, sampler=sampler) val_dataloader = DataLoader(val_data, batch_size=cfg.BATCH_SIZE) test_dataloader = DataLoader(test_data, batch_size=cfg.BATCH_SIZE) |
To deal with the problem of imbalanced datasets, we are applying the oversampling technique, which essentially needs to specify the exact weight for every single feature in our entire dataset.
On line 72, all the labels within the training set are being extracted.
From lines 75 – 76, the Counter subclass is used to count each label within each category, and as a result, the output is in the form of a dictionary where the key represents the label and the value corresponds to the total number of available samples.
Lines 80 – 81 computes the weight that’s applied to each class depending on the number of samples that are available (based on the output from classCount)
Lines 86 – 89 specify each sample’s weight in our entire dataset. At the start, each sample is initialized to 0’s. Then, we will take out the class weight for each class and update the sample weight.
Lines 92 – 93, initialize the WeightedRandomSampler class to sample the elements based on the passed weights (sampleWeight), which will use for handling the imbalanced dataset and set replacement equals to true as to see the dataset multiple times as we iterate through the dataset.
Next, lines 96 – 98, create a loader that will help return our loaded dataset in batches while training the network and specify the sampler to be the WeightedRandomSampler defined in lines 92– 93.
100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | # initialize the model and send it to device model = EmotionNet(num_of_channels=1, num_of_classes=num_of_classes) model = model.to(device) # initialize our optimizer and loss function optimizer = SGD(params=model.parameters(), lr=cfg.LR) criterion = nn.CrossEntropyLoss() # initialize the learning rate scheduler and early stopping mechanism lr_scheduler = LRScheduler(optimizer) early_stopping = EarlyStopping() # calculate the steps per epoch for training and validation set train_steps = len(train_dataloader.dataset) // cfg.BATCH_SIZE val_steps = len(val_dataloader.dataset) // cfg.BATCH_SIZE # initialize a dictionary to save the training history history = { "train_acc": [], "train_loss": [], "val_acc": [], "val_loss": [] } |
Now we have that all setup, let’s initialize our model. Since the Fer2013 dataset is grayscale, we modify num_of_channels=1 and num_of_classes=6.
We also call to(device) to move the model to either on our CPU or GPU if available ( Line 102).
Lines 105– 106 initialize our optimizer and loss function. We’ll use the Stochastic Gradient Descent optimizer (SGD) for training and the Cross-Entropy Loss function for our loss function.
Lines 109– 110 initialize our learning rate scheduler and early stopping mechanism.
Lines 113 – 114 calculate the steps per epoch for the training and validation based on the batch_size. Then the history variable on Lines 117 – 122 will keep track of the entire training history containing values like training accuracy, training loss, validation accuracy, and validation loss.
Now that all our initialization is done let’s go ahead and train our model.
124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 | # iterate through the epochs print(f"[INFO] Training the model...") start_time = datetime.now() for epoch in range(0, cfg.NUM_OF_EPOCHS): print(f"[INFO] epoch: {epoch + 1}/{cfg.NUM_OF_EPOCHS}") """ Training the model """ # set the model to training mode model.train() # initialize the total training and validation loss and # the total number of correct predictions in both steps total_train_loss = 0 total_val_loss = 0 train_correct = 0 val_correct = 0 # iterate through the training set for (data, target) in train_dataloader: # move the data into the device used for training, data, target = data.to(device), target.to(device) # perform a forward pass and calculate the training loss predictions = model(data) loss = criterion(predictions, target) # zero the gradients accumulated from the previous operation, # perform a backward pass, and then update the model parameters optimizer.zero_grad() loss.backward() optimizer.step() # add the training loss and keep track of the number of correct predictions total_train_loss += loss train_correct += (predictions.argmax(1) == target).type(torch.float).sum().item() |
Before we started training the model, we started a timer to measure how long it will take to train our model (Line 126).
On Lines 128, we start iterating through the number of epochs set within the config.py file. Then set our model to train mode (Line 136) to tell PyTorch we want to update our gradients.
Next, we initialize variable for the following:
- Our training loss and validation loss in each iteration (Lines 140 – 141), and
trainCorrectandvalCorrectvariables to keep track of the number of correct predictions for the current iteration (Lines 142 – 143).
Starting from Line 146, we start a for loop which goes over the DataLoader object, and the benefit of this is that PyTorch automatically yields a portion of the training data for us.
Then for each batch return be, perform the following operation:
- Move the feature and label into the current device available, CPU or GPU (line 148)
- Perform a forward pass through the network to obtain our predictions, then (line 151)
- Calculate the loss (line 152)
Next, we perform these essential operations in PyTorch, which we must handle ourselves:
- Zero the gradients accumulated from the previous operation (line 156)
- Perform backward propagation (line 157)
- Then update the weights of our model (line 158)
Finally, we updated the training loss and training accuracy values within each epoch (lines 161 – 162).
Now we have looped over all the batches in our training set for this current iteration, let’s now evaluate the model on the validation set:
164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 | """ Validating the model """ model.eval() # disable dropout and dropout layers # prevents pytorch from calculating the gradients, reducing # memory usage and speeding up the computation time (no back prop) with torch.set_grad_enabled(False): # iterate through the validation set for (data, target) in val_dataloader: # move the data into the device used for testing data, target = data.to(device), target.to(device) # perform a forward pass and calculate the training loss predictions = model(data) loss = criterion(predictions, target) # add the training loss and keep track of the number of correct predictions total_val_loss += loss val_correct += (predictions.argmax(1) == target).type(torch.float).sum().item() |
The validation function will be very similar to the training function. Except, we don’t need to backpropagate the loss for gradient calculation nor update the model parameters.
One of the important thing to set when evaluation your PyTorch model is to:
- Switch your model into evaluation mode (Line 167) and,
- Turn off PyTorch’s automatic gradients (autograd) using
torch.set_grad_enabled(False)(Line 171)
186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 | # calculate the average training and validation loss avg_train_loss = total_train_loss / train_steps avg_val_loss = total_val_loss / val_steps # calculate the train and validation accuracy train_correct = train_correct / len(train_dataloader.dataset) val_correct = val_correct / len(val_dataloader.dataset) # print model training and validation records print(f"train loss: {avg_train_loss:.3f} .. train accuracy: {train_correct:.3f}") print(f"val loss: {avg_val_loss:.3f} .. val accuracy: {val_correct:.3f}", end='\n\n') # update the training and validation results history['train_loss'].append(avg_train_loss.cpu().detach().numpy()) history['train_acc'].append(train_correct) history['val_loss'].append(avg_val_loss.cpu().detach().numpy()) history['val_acc'].append(val_correct) # execute the learning rate scheduler and early stopping validation_loss = avg_val_loss.cpu().detach().numpy() lr_scheduler(validation_loss) early_stopping(validation_loss) # stop the training procedure due to no improvement while validating the model if early_stopping.early_stop_enabled: break print(f"[INFO] Total training time: {datetime.now() - start_time}...") |
Once we’re out of the validation loop, we’ll calculate the average training and validation loss and accuracy (Lines 187– 192).
Lines 199– 202 helps save both the loss and accuracy after the training and validation procedure into our history dictionary.
Lines 205 – 211 makes a call to the learning rate scheduler and early stopping mechanism to help prevent our model from over-fitting.
Once we are no longer inside the loop, we’ll subtract the current time usingdatetime.now() from the start_time to see how long our model took to train (Line 213).
215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 | # move model back to cpu and save the trained model to disk if device == "cuda": model = model.to("cpu") torch.save(model.state_dict(), args['model']) # plot the training loss and accuracy overtime plt.style.use("ggplot") plt.figure() plt.plot(history['train_acc'], label='train_acc') plt.plot(history['val_acc'], label='val_acc') plt.plot(history['train_loss'], label='train_loss') plt.plot(history['val_loss'], label='val_loss') plt.ylabel('Loss/Accuracy') plt.xlabel("#No of Epochs") plt.title('Training Loss and Accuracy on FER2013') plt.legend(loc='upper right') plt.savefig(args['plot']) |
Lines 216 – 218 moves our model back into CPU if it was in GPU, then saves the model’s weights to a predefined path (Lines 218) and plot the values within the history dictionary (Lines 221 – 231).
233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 | # evaluate the model based on the test set model = model.to(device) with torch.set_grad_enabled(False): # set the evaluation mode model.eval() # initialize a list to keep track of our predictions predictions = [] # iterate through the test set for (data, _) in test_dataloader: # move the data into the device used for testing data = data.to(device) # perform a forward pass and calculate the training loss output = model(data) output = output.argmax(axis=1).cpu().numpy() predictions.extend(output) # evaluate the network print("[INFO] evaluating network...") actual = [label for _, label in test_data] print(classification_report(actual, predictions, target_names=test_data.classes)) |
Now we have our model trained on the training dataset, let’s see how it performs on an unseen dataset. So we will once again turn off PyTorch’s autograd function and set our model into evaluation mode (Lines 235– 237).
Next on line 240, we initialize an empty list called predictions which holds the model’s predictions. From here, we follow the procedure we’ve seen before: loading our dataset into our current device (CPU, or GPU), infer the images into the model, and get our predictions which are populated within the empty list (Lines 243 – 250).
To complete the train.py script, we accessed our model performance using the classification_report from scikit-learn to provide a general overview of the model’s prediction, allowing us to understand which classes our model predicts better/worse compared to the other. Usually, values like precision, recall, f1-score, support and accuracy:
1 2 3 4 5 6 7 8 9 10 11 12 13 | [INFO] evaluating network... precision recall f1-score support angry 0.52 0.60 0.56 1069 fear 0.44 0.36 0.39 1024 happy 0.86 0.75 0.80 1774 neutral 0.54 0.53 0.53 1233 sad 0.43 0.55 0.48 1247 surprise 0.76 0.73 0.74 831 accuracy 0.59 7178 macro avg 0.59 0.58 0.59 7178 weighted avg 0.61 0.59 0.60 7178 |
Display Result
Now that’s implemented, it’s time to run our script. So, fire up your terminal, and execute the following command:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | $ python3 train.py --model output/model.pth --plot output/plot.png [INFO] Current training device: cuda [INFO] Class labels: ['angry', 'fear', 'happy', 'neutral', 'sad', 'surprise'] [INFO] Train samples: 25838 ... Validation samples: 2871... [INFO] Total sample: Counter({2: 6495, 3: 4493, 4: 4347, 0: 3973, 1: 3677, 5: 2853}) [INFO] Training the model... [INFO] epoch: 1/50 train loss: 2.113 .. train accuracy: 0.174 val loss: 1.879 .. val accuracy: 0.152 [INFO] epoch: 2/50 train loss: 1.981 .. train accuracy: 0.212 val loss: 2.055 .. val accuracy: 0.179 [INFO] Early stopping: 1/10... [INFO] epoch: 3/50 train loss: 1.857 .. train accuracy: 0.264 val loss: 1.609 .. val accuracy: 0.336 [INFO] epoch: 4/50 train loss: 1.591 .. train accuracy: 0.361 val loss: 1.436 .. val accuracy: 0.423 [INFO] epoch: 5/50 train loss: 1.439 .. train accuracy: 0.426 val loss: 1.327 .. val accuracy: 0.483 .............................................. [INFO] epoch: 30/50 train loss: 0.917 .. train accuracy: 0.656 val loss: 1.161 .. val accuracy: 0.572 [INFO] Early stopping: 5/10... [INFO] epoch: 31/50 train loss: 0.913 .. train accuracy: 0.657 val loss: 1.163 .. val accuracy: 0.581 Epoch 31: reducing learning rate of group 0 to 2.5000e-02. [INFO] Early stopping: 6/10... [INFO] epoch: 32/50 train loss: 0.855 .. train accuracy: 0.681 val loss: 1.119 .. val accuracy: 0.597 [INFO] Early stopping: 7/10... [INFO] epoch: 33/50 train loss: 0.840 .. train accuracy: 0.685 val loss: 1.142 .. val accuracy: 0.597 [INFO] Early stopping: 8/10... [INFO] epoch: 34/50 train loss: 0.826 .. train accuracy: 0.689 val loss: 1.129 .. val accuracy: 0.589 [INFO] Early stopping: 9/10... [INFO] epoch: 35/50 train loss: 0.816 .. train accuracy: 0.693 val loss: 1.165 .. val accuracy: 0.591 [INFO] Early stopping: 10/10... [INFO] Early stopping enabled [INFO] Time taken to complete training the model: 0:14:00.241209... [INFO] evaluating network... precision recall f1-score support angry 0.52 0.60 0.56 1069 fear 0.44 0.36 0.39 1024 happy 0.86 0.75 0.80 1774 neutral 0.54 0.53 0.53 1233 sad 0.43 0.55 0.48 1247 surprise 0.76 0.73 0.74 831 accuracy 0.59 7178 macro avg 0.59 0.58 0.59 7178 weighted avg 0.61 0.59 0.60 7178 |
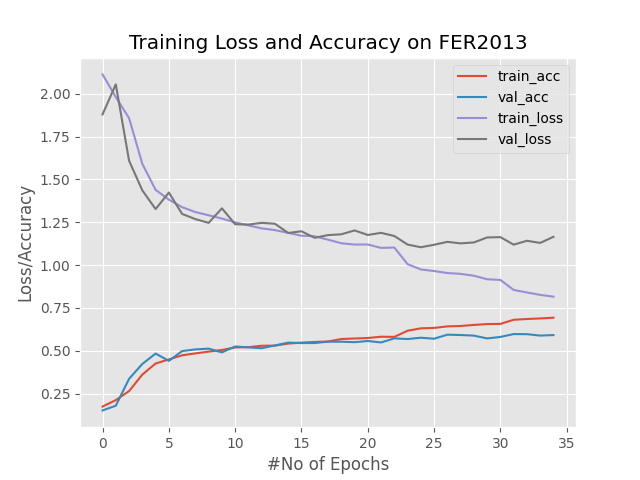
Training our Emotion network took ≈ 14 minutes on my GPU and at the 35 iteration our network stopping training as due to the early stopping mechanism that was built and added during the training process.
At the end we obtained 69.30% training accuracy and 59.10% validation accuracy.
When we evaluated the model on our testing set, we reached an accuracy of 59% based on the F1-score metrics.
Finally the figure you can see above demonstrates the loss and accuracy of the whole training process.
Summary
In this tutorial, you learned quite some useful concepts related to using the PyTorch deep learning library.
You learnt how to:
- Handle imbalanced datasets
- How to build your own custom neural network.
- Train/Validate your PyTorch model from scratch using Python, and
- How to use your trained PyTorch model to make predictions on new images.
To end this tutorial, can our model achieve much higher training/validation/ evaluation results? Well, I would say it’s possible; however, from what I’ve noticed while preparing the FER2013 dataset before I began training it, I noticed a few challenges that were possible to arise, which are:
- Due to the different variety of human faces shown
- Different lighting conditions and facial pose.
What’s Next?
Now, what’s next? in the following tutorial, we will explore the library OpenCV’s functionalities. Until then, share, like the video above, comment, and subscribe.
Further Reading
We have listed some useful resources below if you thirst for more reading.
- What You Don’t Know About Machine Learning Could Hurt You
- Linear Regression using Stochastic Gradient Descent in Python
- 3 Rookie Mistakes People Make Installing OpenCV | Avoid It!
- Why is Python the most popular language for Data Science
- A Simple Walk-through with NumPy for Data Science
- Why Google and Microsoft uses OpenCV




