
In this post, we will talk about the essential concepts in the library Pandas. You will see It’s one of the most important libraries used for data processing, efficient storage, and manipulation of densely typed arrays in Python. We will also see that it is a continuation of the NumPy tutorial. Without further ado, let’s start!.
This tutorial is part one in our three-part series on the fundamentals of Pandas:
- Part #1: A simple walk-through with Pandas for Data Science, Part 1 (today’s post)
- Part #2: A simple walk-through with Pandas for Data Science, Part 2 (next weeks tutorial)
- Part #3: How to import existing files with Pandas (blog post two weeks from now)
Prerequisites
Before starting with this tutorial, I strongly recommend you get familiar with Python programming terminology and NumPy. To understand this tutorial, you need to get your foundations appropriately built.
What is Pandas?
If you have carefully followed the tutorial on Numpy, you will have learned that NumPy lies at the core of a rich ecosystem of data science libraries. What this means is that most of the data science libraries utilize the power of NumPy. Let’s have a careful look at the image below:
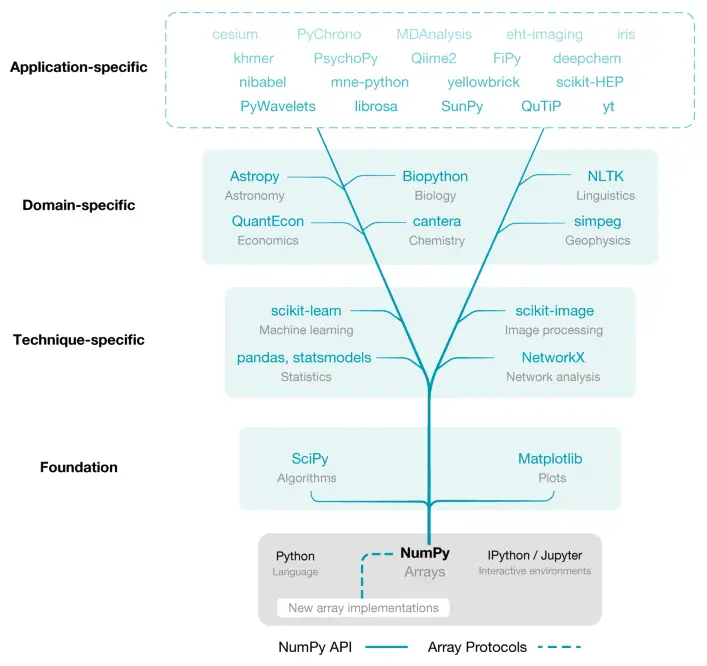
After a well-detailed study of the photo, you will spot that the Pandas package is built on top of NumPy.
There is something you should keep in mind about Numpy. It will provide you with the basic features when you have well-organized data. However, there are several drawbacks are when more functionality is required. Such as:
- Linking the rows and columns of labels to data (values)
- Working with heterogeneous types of data
- Missing data, and
- When performing powerful operations such as grouping data to analyze less structured data in different forms.
Let’s see how we can install this package, then explore some of the basic functionalities which are the basics of Pandas.
How to Install and Use Pandas?
If you have Anaconda installed on your computer already. In that case, you may skip this process since Pandas comes along with Anaconda, which includes Data Science packages suitable for Linux, Windows, and macOS.
If you don’t have the library already installed or you’re not using Anaconda, I strongly recommend installing it to avoid missing dependencies. Or you may choose to ignore me by entering these commands on your command line:
1 2 | $ pip install numpy $ pip install pandas |
Once you have followed the tutorial or went ahead to install the Anaconda Stack, you should have Pandas installed. Once installed, you can import the library and check the current version with the following commands:
1 2 3 | import pandas as pd print(pd.__version__) # '1.1.4.' |
Note the pd added is a standard convention to renaming libraries which we will do each time we import Pandas.
Auto-Completion
Before starting this tutorial, it’s good to know about using the tab-completion feature; this way, you can quickly explore all the contents of a package. For example, we can show all the contents of the pandas namespace by typing:
1 | pd.<TAB> |
This auto-completion feature also applies to other libraries, including NumPy.
Creating Pandas Objects
There are two (2) common types of data structures in Pandas:
- Series – one-dimensional arrays
- DataFrame – a two-dimensional array
And one more called the Index.
Let’s understand the underlying concept of how we may work with these two libraries. We may begin by opening a script pandas_tutorial.py or pandas_tutorial.ipynb (A Jupyter notebook).
 →
→ Start with importing both libraries (NumPy and Pandas) into our working script.
1 2 | import numpy as np import pandas as pd |
pandas.Series()
pandas.Series can be thought of as a one-dimensional array with indexes. If you want to create one, there are multiple ways you can do so by using either:
- Python Lists
- Python Dictionaries
- NumPy arrays
- Scalar value or Constant
Python Lists
First, I will show you how you can do this with Python lists.
As you can see, inside the parentheses of the Series object created, it contains both a segment of values and indexes. Luckily Pandas provides the capability which lets us access the values and index attributes.
1 2 3 4 5 6 7 8 9 | data = pd.Series(data=[0, 1, 2, 3], index=['first', 'second', 'third', 'fourth']) print(data) # ------ output ------- # first 0 # second 1 # third 2 # fourth 3 # dtype: int64 |
You can think of the Index as an array-like object of type pd.Index, which I will further explain below. For now, knowing that they exist is enough.
1 2 3 4 | # get the index print(data.index) # ------ output ------- # Index(['first', 'second', 'third', 'fourth'], dtype='object') |
The values are similar to what we learned about NumPy.
1 2 3 4 | # get the values print(data.values) # ------ output ------- # [0 1 2 3] |
Using NumPy arrays, data can be accessed by the corresponding Index via square-bracket notation:
1 2 3 4 5 6 7 8 9 10 11 | # get the first value in a series print(data[0]) # ------ output ------- # 0 # access the first 2 data stored in the series print(data[0:2]) # ------ output ------- # first 0 # second 1 # dtype: int64 |
So far, we have seen how data can be accessed by a Numpy implicitly defined integer index. However, this can be done by an explicitly defined Index associated with the values created above. For example, we can use the strings as an index:
1 2 3 4 5 6 7 8 9 10 11 | # get the first value in a series print(data['first']) # ------ output ------- # 0 # access the first 2 data stored in the series print(data['first':'second']) # ------ output ------- # first 0 # second 1 # dtype: int64 |
Dictionaries
The second way to create a Pandas Series is by using a dictionary.
Let’s start by creating a Python dictionary. If you don’t know what they are, visit this tutorial here :
1 2 3 4 5 6 7 8 9 | data_dict = { "first" : 0, "second" : 1, "third" : 2, "fourth" : 3 } print(data_dict) # ------ output ------- # {'first': 0, 'second': 1, 'third': 2, 'fourth': 3} |
In order to create a Series object out of a Python dictionary, we can do it this way:
1 2 3 4 5 6 7 8 | data = pd.Series(data_dict) print(data) # ------ output ------- # first 0 # second 1 # third 2 # fourth 3 # dtype: int64 |
NumPy Array
We can also create one where specifying the Index is optional as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 | array = np.arange(4) print(array) # ------ output ------- # [0 1 2 3] data = pd.Series(array) print(data) # ------ output ------- # 0 0 # 1 1 # 2 2 # 3 3 # dtype: int64 |
Scalar Value or Constant
Then, if you have a scenario where the data needs to be a scalar or a constant, we can fill up to an index specified.
1 2 3 4 5 6 7 8 | print(pd.Series(10, index=[1, 2, 3, 4, 5])) # ------ output ------- # 1 10 # 2 10 # 3 10 # 4 10 # 5 10 # dtype: int64 |
pandas.DataFrame()
Let’s say we want to represent different top tech companies. Assuming you are familiar with Python dictionaries we will have keys and values.
To represent a company like Google, we have the key as ‘name’ and value as ‘Google’ and another key ‘year’ with the value as 1998. This way we have represented data for a single tech company. However, the downside of writing it this way is representing data for more tech companies like Facebook and thousands more becomes complicated. Writing it this way isn’t efficient enough.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | company_info1 = { 'name' : 'Google', 'year' : 1998 } print(company_info1) # ------ output ------- # {'name': 'Google', 'year': 1998} company_info2 = { 'name' : 'Facebook', 'year' : 2004 } print(company_info2) # ------ output ------- # {'name': 'Facebook', 'year': 2004} |
The way I will suggest you think about this is to represent all the values as a list. Let’s see how this will look like below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | tech_companies = ['Google', 'Facebook', 'Nvidia', 'Microsoft'] year_founded = [1998, 2004, 1993, 1975] companies_info = pd.DataFrame({ 'name' : tech_companies, 'year' : year_founded }) print(companies_info) # ------ output ------- # # | name | year | # ------------------------ # 0 | Google | 1998 | # 1 | Facebook | 2004 | # 2 | Nvidia | 1993 | # 3 | Microsoft | 1975 | |
We can also access the index labels from the pandas.DataFrame Object created like the Series object as well as the column attribute, which is an Index object holding the column labels:
1 2 3 4 5 6 7 | print(companies_info.index) # ------ output ------- # RangeIndex(start=0, stop=4, step=1) print(companies_info.columns) # ------ output ------- # Index(['name', 'year'], dtype='object') |
To access the values of a single column, we can write as follow:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # get the values on the column 'name' print(companies_info['name']) # ------ output ------- # 0 Google # 1 Facebook # 2 Nvidia # 3 Microsoft # Name: name, dtype: object # get the values on the column 'year' print(companies_info['year']) # ------ output ------- # 0 1998 # 1 2004 # 2 1993 # 3 1975 # Name: name, dtype: object |
You can also think about pandas.DataFrames as two-dimensional NumPy arrays, where both the rows and columns have a generalized index for accessing the data.
pandas.Index()
You might have noticed up until now that both the pandas.DataFrame and pandas.Series contain an explicit index that quickly allows us to get values or modify values within the existing data. According to the documentation provided, these indexes are nothing more than an Immutable n-dimensional array which stores the axis labels for all Pandas objects.
Let’s run an experiment and construct an Index from a list of Integers:
1 2 3 4 | index = pd.Index(np.arange(6)) print(index) # ------ output ------- # Int64Index([0, 1, 2, 3, 4, 5], dtype='int64') |
This Index object also supports many operations like NumPy arrays.
Take Python Indexing notation as an example to retrieve values or slices:
1 2 3 4 5 6 7 | print(index[2]) # ------ output ------- # 2 print(index[2:4]) # ------ output ------- # Int64Index([2, 3], dtype='int64') |
These Immutable objects also have many attributes such as:
1 2 3 4 5 6 7 8 9 | print(index.shape) # get the shape print(index.size) # get the size print(index.ndim) # shape of the dimension print(index.dtype) # data type # ------ output ------- # (6, ) # 6 # 1 # int64 |
They are called immutable objects for one reason, and that’s because you can’t modify them.
1 2 3 | index[0] = 2 # ------ output ------- # TypeError: Index does not support mutable operations |
This operation will certainly raise a TypeError: “Index does not support mutable operations.”
Data Indexing and Selection
If you have read the previous tutorial related to NumPy arrays, you will have learned how you can access, set, and modify values within NumPy arrays created. If you’ve learned that, there’s no need to stress out. There is only a few features you need to know.
When you perform either data indexing or selection on a Pandas Object (Series or DataFrame), it’s very similar to the pattern used in NumPy arrays.
Let’s learn about performing such an operation on a Pandas Series object, then move on to working with a pandas.DataFrame object.
Data Indexing and selection in Series
Let’s create a pandas.Series and perform some basic selection and indexing techniques as we would with NumPy arrays:
1 2 3 4 5 6 7 8 9 | continent = pd.Series(data=['Africa', 'Europe', 'Asia', 'North America'], index=['Nigeria', 'Serbia', 'China', 'USA']) print(continent) # ------ output ------- # Nigeria Africa # Serbia Europe # China Asia # USA North America # dtype: object |
We can even decide to modify this pandas.Series object by adding a unique key and assigning a new index value to the new key.
1 2 3 4 5 6 7 8 9 | continent['Suriname'] = "South America" print(continent) # ------ output ------- # Nigeria Africa # Serbia Europe # China Asia # USA North America # Suriname South America # dtype: object |
One difference when performing slicing, which we talked about in the tutorial related to NumPy, is that there are two different ways slicing behaves.
- The Explicit index style ( continent [ ‘Nigeria’ , ‘China’ ] ): The last Index is included in the slice.
- The Implicit index style ( continent [ 0 : 2 ] ): The last Index isn’t included in the slice.
You may confirm from the output below. Remember, we start counting from 0 instead of 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 | print(continent['Nigeria':'China']) # ------ output ------- # Nigeria Africa # Serbia Europe # China Asia # dtype: object print(continent[0:2]) # ------ output ------- # Nigeria Africa # Serbia Europe # China Asia # dtype: object |
Indexer: loc and iloc
Since these indexing types often cause confusion, special indexer attributes were created to resolve this issue.
The first one is the .loc attribute, which refers to the explicit Index with which we may get rows or columns with particular labels from the Index:
1 2 3 4 5 6 7 | print(continent.loc['Serbia': 'Suriname']) # ------ output ------- # Serbia Europe # China Asia # USA North America # Suriname South America # dtype: object |
The second one is the .iloc attribute, which refers to the implicit Index with which we can get rows or columns at a particular position in the Index (Note: it only takes integers):
1 2 3 4 5 6 7 8 9 10 | print(continent.iloc[0]) # ------ output ------- # Africa print(continent.iloc[0:3]) # ------ output ------- # Nigeria Africa # Serbia Europe # China Asia # dtype: object |
Data Indexing and selection in DataFrames
Moving on to more complex structured arrays (DataFrames), you can think of it as a two-dimensional structured array.
Let’s create a pandas.DataFrame with multiple pandas.Series objects such as continents, language, and population, and specify the Index as a country located within that region.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | continent = pd.Series(data=['Africa', 'Europe', 'Asia', 'North America'], index=['Nigeria', 'Serbia', 'China', 'USA']) language = pd.Series(data=['English', 'Serbian', 'Mandarin', 'English'], index=['Nigeria', 'Serbia', 'China', 'USA']) population = pd.Series(data=[195900000, 6964000, 1393000000, 328200000], index=['Nigeria', 'Serbia', 'China', 'USA']) data = pd.DataFrame({'continent': continent, 'language': language, 'population' : population}) print(data) # ------ output ------- # continent language population # Nigeria Africa English 195900000 # Serbia Europe Serbian 6964000 # China Asia Mandarin 1393000000 # USA North America English 328200000 |
To get all the values within a row, we can pass a single index to an array:
1 2 3 | print(data.values[3]) # ------ output ------- # ['North America' 'English' 328200000] |
and giving an available index to the pandas.DataFrame, we can get all the languages within the column.
1 2 3 4 5 6 7 | print(data['language']) # OR print(data.language) # ------ output ------- # Nigeria English # Serbia Serbian # China Mandarin # USA English # Name: language, dtype: object |
As mentioned earlier, we can use these pandas indexers: loc and iloc. The only underlying difference is we need to specify the index and column labels to access a value, sample, or multiple rows within our DataFrame:
1 2 3 4 5 6 7 8 9 10 11 12 | print(data.iloc[:2, :2]) # ------ output ------- # continent language # Nigeria Africa English # Serbia Europe Serbian print(data.loc[:'China', 'language']) # ------ output ------- # Nigeria English # Serbia Serbian # China Mandarin # Name: language, dtype: object |
Similarly, direct masking operations are also interpreted row-wise rather than column-wise: we can perform direct masking operations by selecting only the rows with a population greater than ten million.
1 2 3 4 5 6 7 | ten_million = 10000000 print(data[data.population > ten_million]) # ------ output ------- # continent language population # Nigeria Africa English 195900000 # China Asia Mandarin 1393000000 # USA North America English 328200000 |
To break down how this works, first, we can use boolean arrays as masks to select a particular subset of the data, which returns either true or false based on the condition. Now to choose the values from the array, we can index based on the boolean array. That’s why we get the result above.
1 2 3 4 5 6 7 | print(data.population > ten_million) # ------ output ------- # Nigeria True # Serbia False # China True # USA True # Name: population, dtype: bool |
Using these indexers, we can combine both masking (just explained) and fancy indexing to return only a specific column of interest.
1 2 3 4 5 6 7 | ten_million = 10000000 print(data.loc[data.population > ten_million, ['continent']]) # ------ output ------- # continent # Nigeria Africa # China Asia # USA North America |
Then we can choose to either modify or set values into our DataFrame, the same way you have seen with NumPy.
1 2 3 4 5 6 7 8 | print(data.iloc[0, 2] ) # ------ output ------- # 195900000 data.iloc[0, 2] = 195900123 print(data.iloc[0, 2] ) # ------ output ------- # 195900123 |
You should click on the “Click to Tweet Button” below to share on twitter.
Check out the post on a simple walk-through with Pandas. Share on XConclusion
In this post, you discovered the fundamentals behind the Pandas Library. You learned how to create Pandas Objects, and perform data indexing and selection on both Pandas Objects (Series and DataFrame).
In the next tutorial we will learn how to perform different operations with Pandas, how to handle missing data, combining different datasets, and finally about groupby functions along with computing functions like aggregate, apply, filter and transform.
Do you have any questions about Pandas or this post? Leave a comment and ask your question. I’ll do my best to answer.
Further Reading
We have listed some useful resources below if you thirst for more reading.
Articles
- How to import existing files with Pandas
- Pandas Docs: Merge, join, concatenate and compare
- A Simple Walk-through with Python for Data Science
- A Simple Walk-through with NumPy for Data Science
- Why is Python the most popular language for Data Science
- What You Don’t Know About Machine Learning Could Hurt You
Books
To be notified when this next blog post goes live, be sure to enter your email address in the form !





2 Comments
I Αppreciate the effort put into these tutorials. Thank you.
You’re welcome Caitlyn.